
One of the awesome things about Python is how relatively simple it is to do pretty complex and impressive tasks. A great example of this is web scraping.
This is an article about web scraping with Python. In it we will look at the basics of web scraping using popular libraries such as requests and beautiful soup.
Topics covered:
- What is web scraping?
- What are
requestsandbeautiful soup? - Using CSS selectors to target data on a web-page
- Getting product data from a demo book site
- Storing scraped data in CSV and JSON formats
What is Web Scraping?
Some websites can contain a large amount of valuable data. Web scraping means extracting data from websites, usually in an automated fashion using a bot or web crawler. The kinds or data available are as wide ranging as the internet itself. Common tasks include
- scraping stock prices to inform investment decisions
- automatically downloading files hosted on websites
- scraping data about company contacts
- scraping data from a store locator to create a list of business locations
- scraping product data from sites like Amazon or eBay
- scraping sports stats for betting
- collecting data to generate leads
- collating data available from multiple sources
Legality of Web Scraping
There has been some confusion in the past about the legality of scraping data from public websites. This has been cleared up somewhat recently (I’m writing in July 2020) by a court case where the US Court of Appeals denied LinkedIn’s requests to prevent HiQ, an analytics company, from scraping its data.
The decision was a historic moment in the data privacy and data regulation era. It showed that any data that is publicly available and not copyrighted is potentially fair game for web crawlers.
However, proceed with caution. You should always honour the terms and conditions of a site that you wish to scrape data from as well as the contents of its robots.txt file. You also need to ensure that any data you scrape is used in a legal way. For example you should consider copyright issues and data protection laws such as GDPR. Also, be aware that the high court decision could be reversed and other laws may apply. This article is not intended to prvide legal advice, so please do you own research on this topic. One place to start is Quora. There are some good and detailed questions and answers there such as at this link
One way you can avoid any potential legal snags while learning how to use Python to scrape websites for data is to use sites which either welcome or tolerate your activity. One great place to start is to scrape – a web scraping sandbox which we will use in this article.
An example of Web Scraping in Python
You will need to install two common scraping libraries to use the following code. This can be done using
pip install requests
and
pip install beautifulsoup4
in a command prompt. For details in how to install packages in Python, check out Installing Python Packages with Pip.
The requests library handles connecting to and fetching data from your target web-page, while beautifulsoup enables you to parse and extract the parts of that data you are interested in.
Let’s look at an example:
import csv
import json
import requests
from requests.exceptions import ConnectionError
from bs4 import BeautifulSoup
if __name__ == "__main__":
url = "http://books.toscrape.com/"
try:
request = requests.get(url)
soup = BeautifulSoup(request.text, "html.parser")
products = soup.find_all(class_="product_pod")
data = []
for product in products:
title = product.find("h3").text
price = float(product.find("div", class_="product_price").find("p", class_="price_color").text.strip("£"))
data.append((title, price))
store_as_csv(data, headings=["title", "price"])
store_as_json(data)
print("### RESULTS ###")
for item in data:
print(*item) # Don't let this phase you - it just unpacks the tuples for nicer display.
except ConnectionError:
print("Unable to open url.")
So how does the code work?
In order to be able to do web scraping with Python, you will need a basic understanding of HTML and CSS. This is so you understand the territory you are working in. You don’t need to be an expert but you do need to know how to navigate the elements on a web-page using an inspector such as chrome dev tools. If you don’t have this basic knowledge, you can go off and get it (w3schools is a great place to start), or if you are feeling brave, just try and follow along and pick up what you need as you go along.
To see what is happening in the code above, navigate to http://books.toscrape.com/. Place your cursor over a book price, right-click your mouse and select “inspect” (that’s the option on Chrome – it may be something slightly different like “inspect element” in other browsers. When you do this, a new area will appear showing you the HTML which created the page. You should take particular note of the “class” attributes of the elements you wish to target.
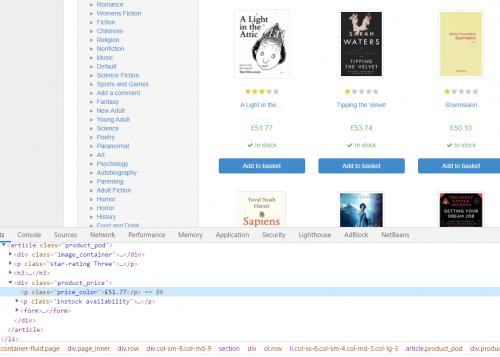
In our code we have
products = soup.find_all(class_="product_pod")
This uses the class attribute and returns a list of elements with the class product_pod.
Then, for each of these elements we have:
title = product.find("h3").text
price = float(product.find("div", class_="product_price").find("p", class_="price_color").text.strip("£"))
The first line is fairly straightforward and just selects the text of the h3 element for the current product. The next line does lots of things, and could be split into separate lines. Basically, it finds the p tag with class price_color within the div tag with class product_price, extracts the text, strips out the pound sign and finally converts to a float. This last step is not strictly necessary as we will be storing our data in text format, but I’ve included it in case you need an actual numeric data type in your own projects.
Storing Scraped Data in CSV Format
csv (comma-separated values) is a very common and useful file format for storing data. It is lightweight and does not require a database.
Add this code above the if __name__ == "__main__": line
def store_as_csv(data, headings=None): # Don't use headings=[] as default argument. It behaves weirdly. if headings is None: headings = []
with open("data.csv", "w", encoding="utf-8", newline="") as file:
writer = csv.writer(file)
# write title row
writer.writerow(headings)
# Write data
for item in data:
writer.writerow(item)
and just before the line print("### RESULTS ###"), add this:
store_as_csv(data, headings=["title", "price"])
When you run the code now, a file will be created containing your book data in csv format. Pretty neat huh?
title,price
A Light in the ...,51.77
Tipping the Velvet,53.74
Soumission,50.1
Sharp Objects,47.82
Sapiens: A Brief History ...,54.23
...
Storing Scraped Data in JSON Format
Another very common format for storing data is JSON (JavaScript Object Notation), which is basically a collection of lists and dictionaries (called arrays and objects in JavaScript).
Add this extra code above if __name__ ...:
def store_as_json(data):
# List to store dictionaries containing the data we extracted.
records = []
for item in data:
new_record = {
"title": item[0],
"price": item[1]
}
records.append(new_record)
# Write these to a JSON file.
with open('data.json', 'w') as outfile:
json.dump(records, outfile, indent=4)
and store_as_json(data) above the print("### Results ###") line.
[
{
"title": "A Light in the ...",
"price": 51.77
},
{
"title": "Tipping the Velvet",
"price": 53.74
},
{
"title": "Soumission",
"price": 50.1
},
{
"title": "Sharp Objects",
"price": 47.82
},
...
]
So there you have it – you now know how to scrape data from a web-page, and it didn’t take many lines of Python code to achieve!
Full Code Listing for Python Web Scraping Example
Here’s the full listing of our program for your convenience.
import csv
import json
import requests
from requests.exceptions import ConnectionError
from bs4 import BeautifulSoup
def store_as_csv(data, headings=None): # Don't use headings=[] as default argument. It behaves weirdly.
if headings is None:
headings = []
with open("data.csv", "w", encoding="utf-8", newline="") as file:
writer = csv.writer(file)
# write title row
writer.writerow(headings)
# Write data
for item in data:
writer.writerow(item)
def store_as_json(data):
# List to store dictionaries containing the data we extracted.
records = []
for item in data:
new_record = {
"title": item[0],
"price": item[1]
}
records.append(new_record)
# Write these to a JSON file.
with open('data.json', 'w') as outfile:
json.dump(records, outfile, indent=4)
if __name__ == "__main__":
url = "http://books.toscrape.com/"
try:
request = requests.get(url)
soup = BeautifulSoup(request.text, "html.parser")
products = soup.find_all(class_="product_pod")
data = []
for product in products:
title = product.find("h3").text
price = float(product.find("div", class_="product_price").find("p", class_="price_color").text.strip("£"))
data.append((title, price))
store_as_csv(data, headings=["title", "price"])
store_as_json(data)
print("### RESULTS ###")
for item in data:
print(*item) # Don't let this phase you - it just unpacks the tuples for nicer display.
except ConnectionError:
print("Unable to open url.")
One final note. We have used requests and beautifulsoup for our scraping, and a lot of the existing code on the internet in articles and repositories uses those libraries. However, there is a newer library which performs the task of both of these put together, and has some additional functionality which you may find useful later on. This newer library is requests-HTML and is well worth looking at once you have got a basic understanding of what you are trying to achieve with web scraping. Another library which is often used for more advanced projects spanning multiple pages is scrapy, but that is a more complex beast altogether, for a later article.
Working through the contents of this article will give you a firm grounding in the basics of web scraping in Python. I hope you find it helpful
Happy computing.
