
Scrapy is a powerful Python package that makes it easy to crawl the web and mine data. There are many reasons why people might want to do this (or hire you to do it). For example:
- Competitive pricing of services and products
- Financial trading
- Content aggregation
- Trend analysis
- Automation of human tasks involving data retrieval
- Many more use cases…
Basically any information which is publicly available on the web can be captured via web scraping/crawling, and Scrapy can easily handle both. Generally scraping refers to gathering data from a specific page or site, whereas crawling involves following links on pages to multiple sites, much like a spider moving around on a web… The spider analogy is so appropriate that the programs we use to perform our crawling are actually named “spiders”. To understand just how powerful spiders and web crawling can be, remember that search engines like Google are in essence just very powerful web crawlers.
Previous Knowledge Required for Using Python Scrapy
In this article we are going to cover the very basics of using Scrapy to access data on a webpage. In order to do this, you will need to have some knowledge of the following topics:
- Using terminal commands
- Installing Python packages
- HTML and the structure of webpages
- Basic Object oriented programming with Python
- Inspecting HTML in a browser using Dev Tools
- Working with a virtual environment (optional)
Installing Scrapy for Python
You may be in the habit of using an IDE such as PyCharm to create Python environments, including package installation. This is fine, or you may prefer to simply run pip install Scrapy to install the package.
Creating a new project with Scrapy
Once you have Scrapy installed, open up a terminal in the parent directory of your project and type
scrapy --help just to make sure Scrapy is in fact installed.
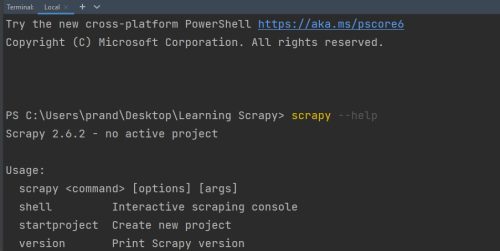
If this is working nicely, now run the command scrapy startproject learning_scrapy
This will set up your project with several directories and files with boilerplate code and lots of useful comments to help you understand what it does. You may want to take a few minutes right now to peruse the project directory just to get a feel for what the various components are. This will help to give you a top-level view that will give you some context for the various details you will be working on as your learning progresses.
Generating your first spider with Scrapy
We are going to retrieve some data from a website designed to give practice with web scraping: https://quotes.toscrape.com/.
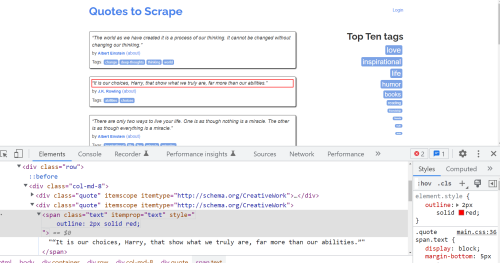
Let’s orientate ourselves a little. Above you can see the page we are going to scrape, with the target text highlighted in red. You can also see Chrome Dev Tools open with the HTML for the target element selected. If you right-click on the <span class="text" itemprop="text">“It is our choices, Harry, that show what we truly are, far more than our abilities.”</span> element, you can copy the XPath, which you will need soon:
/html/body/div/div[2]/div[1]/div[2]/span[1]
You may or may not be familiar with XPaths. They provide a way to navigate through HTML and some other types of document. They are more robust than CSS selectors so we will be using them instead for this series of articles.
When you ran the scrapy startproject learning_scrapy command, the output should have been something like this:
New Scrapy project 'learning_scrapy', using template directory 'C:\Users\...\AppData\Local\Programs\Python\Python310\lib\site-packages\scrapy\templates\project', created in:
C:\Users\...\Desktop\Learning Scrapy\learning_scrapy
You can start your first spider with:
cd learning_scrapy
scrapy genspider example example.com
PS C:\Users\prand\Desktop\Learning Scrapy>
That’s some handy info. Now we can do as suggested and create a spider. Don’t forget to either cd into the correct directory, or use you IDE to open one there.
scrapy genspider quotes quotes.toscrape.com/
You should now have a file called quotes.py in your spiders directory:
import scrapy
class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
pass
We are going to modify the parse method to return the quote we want, using the XPath we copied earlier:
def parse(self, response):
return {'target': response.xpath('//html/body/div/div[2]/div[1]/div[2]/span[1]/text()').get()}
This tells scrapy to parse the response and return a dictionary containing the key target and the value of the text retrieved from the XPath.
Now it’s time to run your spider. You do this with scrapy runspider spiders/quotes.py if your terminal is open in the directory about where your spiders live.
Ta da! In amongst the output from running that spider, if you either scroll through it or use a search, you will hopefully see the result you sought:
{'target': '“It is our choices, Harry, that show what we truly are, far more than our abilities.”'}
2022-09-12 10:02:03 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2022-09-12 10:02:03 [scrapy.core.engine] DEBUG: Crawled (404) <GET http://quotes.toscrape.com/robots.txt> (referer: None)
2022-09-12 10:02:03 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://quotes.toscrape.com/> (referer: None)
2022-09-12 10:02:03 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes.toscrape.com/>
{'target': '“It is our choices, Harry, that show what we truly are, far more than our abilities.”'}
2022-09-12 10:02:03 [scrapy.core.engine] INFO: Closing spider (finished)
2022-09-12 10:02:03 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 448,
'downloader/request_count': 2,
'downloader/request_method_count/GET': 2,
And that is how to use Scrapy to get data from a web page! Obviously there is a great deal more to learn, but if you successfully achieved what was proposed in this article, you are well on your way to a whole new world of possibilities when it comes to web crawling and data mining. I hope you enjoy your adventure!
Happy computing!