
In this article we are going to learn how to do some basic sentiment analysis with Python, using a wordlist-based approach and the afinn package.
First, you will need to install the package:
pip install afinn
or
pip3 install afinn on Mac/Linux
You will also need to install the following packages in the same way if you haven’t already: google, requests, beautifulsoup,pandas, matplotlib, seaborn.
The basic idea with the afinn package is that we have a wordlist which has a score in terms of positivity or negativity assigned to each word, ranging from -5 (very negative) to +5 (very positive).
For example:
amazes 2
amazing 4
ambitious 2
ambivalent -1
amicable 2
amuse 3
amused 3
amusement 3
amusements 3
anger -3
These scores are used as the basis for the evaluation of a text string.
The process we will follow in this lesson is:
- Use Python to programmatically perform a Google search for a given phrase
- Extract the titles from the URLs provided by the previous step
- Perform sentiment analysis on the titles
- Collate the results into a Pandas dataframe
- Display the results in a graph
It is probably best to use a Jupyter Notebook for the code in this lesson, in order to avoid having to run time-consuming operations each time you make a change, as results are stored in variables which can be reused throughout the notebook. For more information on Jupyter Notebooks, see here.
Using Python to programmatically perform a Google search for a given phrase
The first step is to get the URLs from a Google search and store them in a list. Obviously if you already have a webpage in mind or some text you wish to analyse, you can skip this step.
from googlesearch import search
query = "bunny rabbit" # Try your own search terms
num_results = 30
result_urls = []
for result in search(
query, # The query you want to run
tld="com", # The top level domain
lang="en", # The language
num=10, # Number of results per page
start=0, # First result to retrieve
stop=num_results, # Last result to retrieve
pause=2.0, # Lapse between HTTP requests
):
result_urls.append(result)
result_urls
['https://www.youtube.com/watch?v=hDJkFLnmFHU',
'https://www.youtube.com/watch?v=dpvUQagTRHM',
'https://www.rspca.org.uk/adviceandwelfare/pets/rabbits',
'https://en.wikipedia.org/wiki/Rabbit',
'https://en.wikipedia.org/wiki/Rabbit#Terminology',
'https://en.wikipedia.org/wiki/Rabbit#Taxonomy',
'https://en.wikipedia.org/wiki/Rabbit#Biology',
'https://en.wikipedia.org/wiki/Rabbit#Ecology',
'https://www.petakids.com/save-animals/never-buy-bunnies/',
...
Scraping Headlines with Python for Sentiment Analysis
Next we will use requests and beautifulsoup to scrape the urls retrieved in the last step, and store the results in a new list. For now we will just focus on the first h1 tag on each page visited, as this is a good place to start if we are looking for headlines.
import requests
from bs4 import BeautifulSoup
title_list = []
for url in result_urls:
try:
r = requests.get(url, timeout=3)
soup = BeautifulSoup(r.content, "html.parser")
html_element = soup.find("h1")
article_title = html_element.text.strip()
title_list.append(article_title)
except Exception as e:
pass # ignore any pages where there is a problem
title_list
'9 Reasons Why You Shouldn’t Buy a Bunny',
'My House Rabbit',
'What’s The Difference Between A Bunny, A Rabbit, And A Hare?',
'Rabbit',
'406 Not Acceptable',
'Rabbit Behavior',
'14 Fascinating Facts About Rabbits',
'Bunny Rabbit',
...
Performing Sentiment Analysis using Afinn
Now we move on to using the afinn package to perform the actual sentiment analysis. Once we have the results, stored in lists, we create a pandas dataframe for each display and analysis of the results.
from afinn import Afinn
import pandas as pd
af = Afinn()
# Compute sentiment scores and categories
sentiment_scores = [af.score(article) for article in title_list]
sentiment_category = ['positive' if score > 0 else 'negative' if score < 0 else 'neutral' for score in sentiment_scores]
# Create Pandas dataframe from results and display
df = pd.DataFrame([title_list, sentiment_scores, sentiment_category]).T # .T: swap rows and cols
df.columns = ['headline', 'sentiment_score', 'sentiment_category']
df['sentiment_score'] = df.sentiment_score.astype('float')
df.describe()
This gives us some descriptive statistics for the dataframe. Notice that there is an overall mean score of 0.233.., meaning a slight positive sentiment, if our results were statistically significant (which they probably aren’t – see further down for why).
| sentiment_score | |
|---|---|
| count | 30.000000 |
| mean | 0.233333 |
| std | 1.194335 |
| min | -2.000000 |
| 25% | 0.000000 |
| 50% | 0.000000 |
| 75% | 0.000000 |
| max | 4.000000 |
Here’s the dataframe itself:
| headline | sentiment_score | sentiment_category | |
|---|---|---|---|
| 0 | Before you continue to YouTube | 0.0 | neutral |
| 1 | Before you continue to YouTube | 0.0 | neutral |
| 2 | Navigation | 0.0 | neutral |
| 3 | Rabbit | 0.0 | neutral |
| 4 | Rabbit | 0.0 | neutral |
| 5 | Rabbit | 0.0 | neutral |
| 6 | Rabbit | 0.0 | neutral |
| 7 | Rabbit | 0.0 | neutral |
| 8 | 9 Reasons Why You Shouldn’t Buy a Bunny | 0.0 | neutral |
| 9 | My House Rabbit | 0.0 | neutral |
| 10 | What’s The Difference Between A Bunny, A Rabbi… | 0.0 | neutral |
| 11 | Rabbit | 0.0 | neutral |
| 12 | 406 Not Acceptable | 1.0 | positive |
| 13 | Rabbit Behavior | 0.0 | neutral |
| 14 | 14 Fascinating Facts About Rabbits | 3.0 | positive |
| 15 | Bunny Rabbit | 0.0 | neutral |
| 16 | Error\n1020 | -2.0 | negative |
| 17 | 0.0 | neutral | |
| 18 | 13 Rabbit Facts Prove the Point: Bunnies Aren’… | 0.0 | neutral |
| 19 | Pet Rabbits and Your Health | 0.0 | neutral |
| 20 | Rabbit & Bunny Soft Toys | 0.0 | neutral |
| 21 | A Complete Guide to the Best Rabbit Breeds | 3.0 | positive |
| 22 | John Lewis & Partners Bunny Rabbit Plush Soft Toy | 0.0 | neutral |
| 23 | Bunny vs Rabbit – Find out what’s the difference! | 0.0 | neutral |
| 24 | Bunny snatched: Record-holding giant rabbit st… | -2.0 | negative |
| 25 | 10 hopping fun rabbit facts! | 4.0 | positive |
| 26 | Bunny Rabbit Knitting Kit and Pattern | 0.0 | neutral |
| 27 | Bunny, Rabbit & Hare, Oh My! What’s The Differ… | 0.0 | neutral |
| 28 | KitKat Bunny opens the doors to its brand new … | 0.0 | neutral |
| 29 | Petfinder is currently undergoing updates to h… | 0.0 | neutral |
As you can see, a lot of what we collected is “noise”. However there is some useful data to work with. One improvement might be to remove the search term itself from the “headlines” using the pandas replace method.
Plotting Sentiment Analysis Results Using Seaborn
Now let’s plot the results. Plotting with seaborn is a breeze. There are many types of plot available but here we will use countplot as it meets our needs nicely.
import seaborn as sns
import matplotlib.pyplot as plt
plt.style.use("seaborn")
fig, axes = plt.subplots()
bp = sns.countplot(x="sentiment_score", data=df, palette="Set2").set_title(
f"Sentiment Analysis with Python. Search Term: {query}"
)
plt.show()
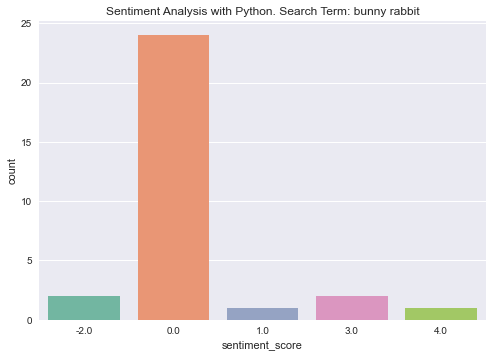
Interpreting the results
Although the results from this activity are potentially quite interesting, we should not be be too serious about any conclusions we draw from them. Generally speaking the contents of an h1 tag are insufficient to make meaningful inferences about a post’s sentiment. The main point of the article was to get you started with sentiment analysis with Python, and provide you with a few tools you can use in your own investigations. For more insightful results, perhaps focus on a single webpage or document. It’s up to you whether you collect your data manually or use something like what we did above with beautifulsoup to scrape it from a webpage. Use the ideas here as a springboard, and have fun.
In this article we have learned how to perform basic sentiment analysis with Python. We used Python to perform a Google search and then scraped the results for headlines. We then analysed the headlines for sentiments score and created a dataframe from the results and displayed them in a graph. I hope you found the article interesting and helpful.
Happy computing!